Healthcare Payments Compliance &
Spend Analytics
> Production-grade Star Schema data warehouse built on 15.4M records of 2024 CMS Open Payments federal healthcare data. Flagged $11.7M in provider payment compliance exposure and a $170M+ anomaly event. Currently migrating to BigQuery on GCP.
Compliance Exposure
$11.7M
Provider Payment Risk Flagged
Scale Processed
15M+
Data Points Engineered
Hidden Insights
18%
Inventory Volume Recovered
Performance
Sub-second
OLAP Query Execution
Operational Intelligence Dashboard
The front-end analytics layer built on 2024 CMS Open Payments federal healthcare data — designed for compliance officers and operations leaders to monitor provider payment patterns, geographic distribution, and anomalous spend concentration across the US healthcare provider network.
Business Impact & Strategic Insights
Geographic Provider Payment Analysis
Geospatial mapping of CMS payment flows revealed that San Diego drives significantly higher surgical device payment throughput than Los Angeles, defying population-based assumptions. This finding informs Forward Stocking Location strategy for medical device distributors serving West Coast provider networks — and demonstrates how geographic payment analysis can surface distribution inefficiencies invisible in aggregate reporting.
Payment Concentration & The Whale Curve
Lorenz curve analysis of CMS payment data revealed that over 80% of total payment volume flows to just the TOP 2% of active provider accounts — a concentration pattern with direct implications for pharmaceutical manufacturer contracting and payor network strategy. This level of dependency transforms routine provider attrition into a major financial and compliance event.
Compliance Exposure Tracking
Z-Score thresholds hardcoded directly into SQL automatically isolated anomalous provider payment patterns in the CMS dataset — flagging $11.7M in payments with no associated product code and surfacing an unexpected $170M+ anomaly event. This methodology is directly applicable to healthcare fraud detection, payor audit workflows, and CMS compliance monitoring.
Data Architecture (The "How")
Overcoming the Data Quality Bottleneck
The 2024 CMS Open Payments dataset — 15.4M records of federal healthcare payment transactions — was completely unsuited for executive reporting in raw form. By engineering a Star Schema with a central fact table and five dimension tables (Physicians, Geography, Products, Entities, Time), query performance shifted from minutes to sub-seconds. A 100% checksum audit validated that Source SUM(Amount) matched Warehouse SUM(Amount) exactly — ensuring zero financial data loss during ingestion. Currently migrating to BigQuery on GCP for cloud-native scalability.
The "Hidden Inventory" Discovery
Data buried in secondary columns mapped up to 5 distinct products into single rows. Leveraging a UNION ALL SQL unpivoting algorithm extracted "hidden" inventory volumes that expanded the dataset—revealing legacy supply chain models had been artificially lowering physical product capacity requirements.
Spatial Backend Dominance
Implemented MySQL's ST_Distance_Sphere to
natively measure distances from mapped coordinates to
national logistics hubs. Re-routing this math from the
front-end BI layer to deeply optimized Backend
procedures provided stable execution scales.
Technical Toolkit
Project Summary
"By engineering a production-grade data warehouse on federal CMS healthcare data, we transformed 15.4M raw payment records into a compliance intelligence platform. The back-end Star Schema was the only path to sub-second executive reporting at this scale — and to surfacing $11.7M in risk that was invisible before."
Healthcare Data Engineering Architecture
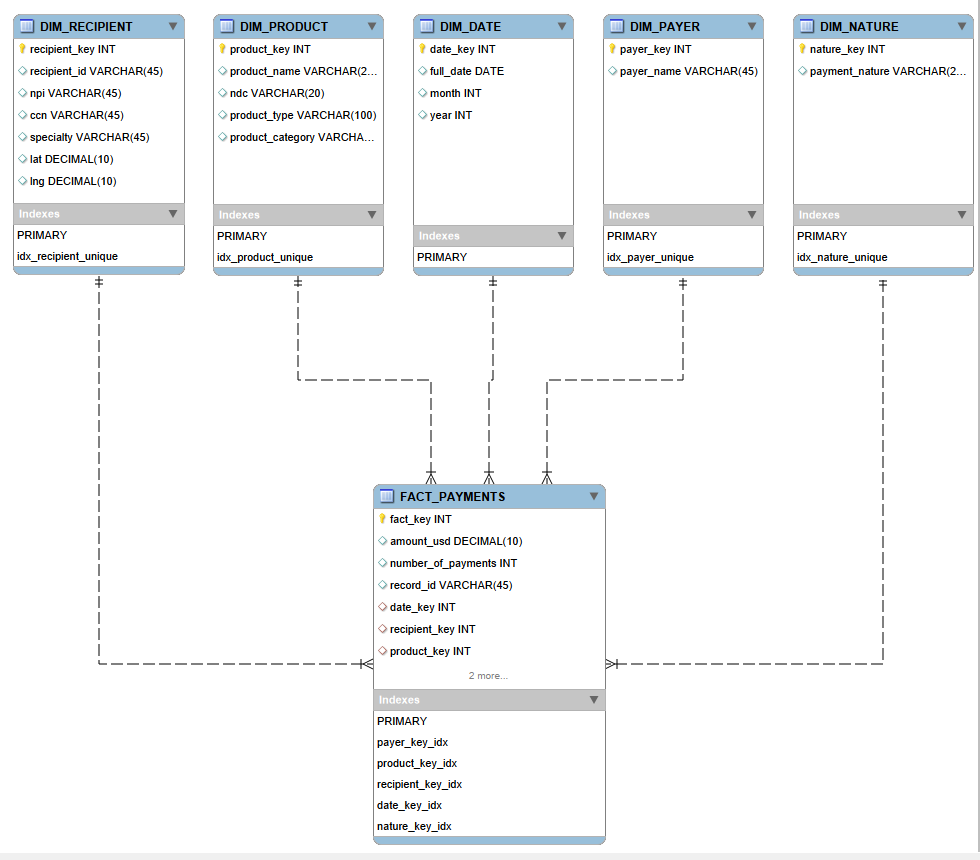
Dimensional Modeling
Optimized Star Schema Design Architecture
Performance Benchmarks
- • Reduced load times from minutes to < 1 sec by shifting aggregation logic to the server.
- • Batch processed updates using cursor-based pagination to prevent transaction log overrides.
01. Architecture Formulation (Star Schema)
Establishing a 15M+ row Fact Table optimized with foreign keys linked to strictly defined dimensions.
-- =========================================================
-- Create Destination Table (Fact Table)
-- =========================================================
DROP TABLE IF EXISTS general_payments;
CREATE TABLE general_payments (
payment_id BIGINT AUTO_INCREMENT PRIMARY KEY,
record_id VARCHAR(50),
payment_date DATE,
amount_usd DECIMAL(15, 2),
number_of_payments INT,
-- Foreign Keys to Dimensions
payment_nature VARCHAR(150),
recipient_type VARCHAR(50),
recipient_specialty VARCHAR(300),
payer_name VARCHAR(150),
etl_created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
UNIQUE INDEX idx_record_id (record_id)
);02. ETL Pipeline (Stored Procedure)
Leveraging batched INSERT IGNORE procedures to
populate dimensions and handle complex geo-joins.
-- Recipient Dimension Generation
SELECT 'Populating DimRecipient...' AS Status;
INSERT IGNORE INTO dim_recipient (
recipient_id, recipient_name, specialty, city, state, zip, lat, lng
)
SELECT
COALESCE(NULLIF(recipient_profile_id, ''), hospital_ccn),
MAX(CASE
WHEN recipient_type LIKE '%Hospital%' THEN hospital_name
ELSE CONCAT(first_name, ' ', last_name) END),
...
FROM general_payments g
-- Hot-patching clean Lat/Lng data via zip crosswalk
LEFT JOIN ref_zip_city z ON LEFT(g.recipient_zip, 5) = z.zip_code
GROUP BY COALESCE(NULLIF(recipient_profile_id, ''), hospital_ccn);